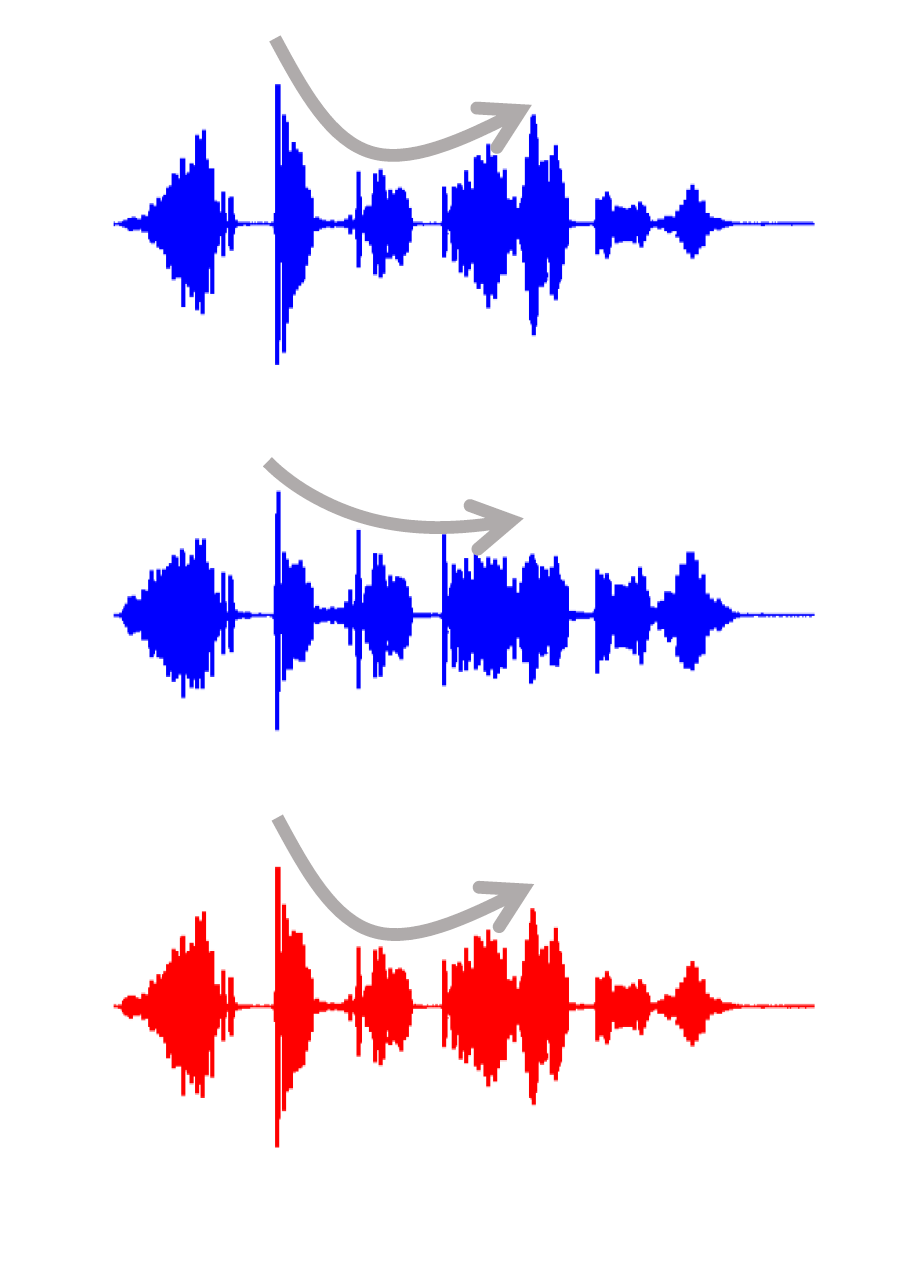
Time series of speech: top – original speech signal, middle – output of a conventional WDRC using CR=2.5, bottom – output of FLEXO DRC. (Signals bandpass filtered: 1.5 kHz to 3 kHz and scaled in magnitude to compensate for added gain). FLEXO_evidence_time_signal